Serverless technology and the rise of the frontend engineer
Serverless computing is a game-changer - delivering huge cost-savings and scalability. You can plug gaps in your service offering by employing Serverless microservices quickly and cheaply.
In this blog-post, I describe what Serverless is by telling the story of how Serverless empowers front-end developers to become web engineers. And don’t worry, if you don’t know what a server is, I’ll start where it all began...
Part 1: The World Wide Web
In the beginning, (well 1989), there was Sir Tim Berners-Lee. Working for CERN, Sir Tim became frustrated by the time it took locating information stored on different computers. His breakthrough was marrying text documents that included references called hyperlinks, to CERN’s computer network - which was also linked to the Internet. These hyperlinked networked documents, which he called, hypertext became the new “World Wide Web”.
Web pages you visit today are written in the very same language as those hyperlinked documents, HTML (HyperText Markup Language). HTML contains the content of the page you are looking at as well as those all-important links.
HTML files are just text documents, written in a particular language that your browser can interpret and display.
When you visit a link to a webpage, you are downloading and viewing an HTML file from another computer. We simply call this computer a Server because it's serving you the HTML file. You are the Client in this relationship.
You might hear people talk about client-side and server-side. Client-side is code that is executed by an internet browser (such as Chrome, Edge, Firefox, or Safari). We also call client-side, the front-end.
HTML documents typically contain links to other files. Some of which tell your browser that it needs that particular file to interpret the page - so it will download those files too before it renders the page you see.
An example of this might be a link to a CSS file which tells your browser how the webpage should look (CSS stands for Cascading Style Sheets). It can also link to JavaScript files which tell your browser how to behave as well as other files such as images.
HTML and CSS are declarative programming languages - they are read from top-to-bottom and that's the order the code is executed by the browser. They portray a description of what the page should be. Like a set of flat-pack assembly instructions, you follow the steps one-by-one and you get a chest of drawers.
Javascript, the third of our front-end musketeers, is an imperative programming language. That means that it uses control flow - the ability to directly manipulate the order of execution of statements in a program.
Control flow means that we can use features such as conditional logic - if this, then do that, else do this other thing - and storing information in references called variables - which can then be referred to in different places throughout your code.
Another feature is the ability to store bits of reusable code into functions - self-contained modules of code that accomplish a specific task. Functions usually take in data, process it, and "return" a result. Once a function is written, it can be used over and over and over again. Really powerful. We’ve just moved from flat-pack furniture to a fully automated assembly line.
Javascript is used to fetch data, animate page elements, validate form inputs and send information about people’s behaviour for analytics, ad tracking and personalisation. There are a whole host of libraries of code written in JavaScript that we can use so we don’t have to write functionality ourselves. We can stand on the shoulders of giants by employing libraries and frameworks (such as React.js) to build our websites.
HTML, CSS and JavaScript are the 3 main technologies which developers use to create webpages. Web developers versed in these client-side languages are typically called front-end developers. This is how I started my web development career, coding simple web pages from scratch.
A frontend developer can get by knowing a little HTML and CSS and rely on JavaScript libraries such as jQuery that make development easier. This is fine for presentational websites but there comes a time when you may need to manage content more efficiently, interact with databases or secure data. So the frontend developer either needs to acquire more skills or team up with a backend developer.
Server-side
When you visit an address on the internet, you are downloading and viewing an HTML document. Sometimes, this HTML is generated dynamically. When a website is requested by a browser on the client-side, the server runs a program to create the HTML and serves this to the client. We call this a web application.
Generating web pages server-side allows you to personalise content for each user and keep secrets safe such as emails, payment details and passwords. You can use templates to create pages in the same format with different content per page.
Content Management Systems (CMSs) such as Wordpress or Drupal, are web applications. Wordpress, for example, consists of a whole bunch of PHP documents (another imperative programming language), a database to store information and a few other associated files.
Alone, the PHP doesn't do anything. Web server software (such as Apache and NGINX) run and compile the PHP code and do a whole host of other clever things, such as handling concurrent requests for webpages, and security features.
There are a large number of programming languages you can write server-side code in. As well as PHP, you can use Python, Java, Ruby and a whole host more. Thanks to a library called Node.js, we can also use our old friend JavaScript server-side. The creation of Node.js has enabled traditional front-end javascript developers to transition more easily to writing back-end code.
Someone who writes both front-end and back-end code is a Full-Stack Web Developer.
Part 2: What is Cloud Computing?
Anyone can run a server from their home computer, as long as it's connected to the internet. So businesses can, (and still do), run on-premise machines - computers dedicated to being servers. The servers are typically stored on a rack, in a dark cupboard or basement. You'll need dedicated people who can monitor the servers, and have the know-how to maintain the software and add software updates.
However, in more recent years, companies have outsourced their servers to third-party providers. Your business no longer has to have a physical server onsite. This on-demand availability of computer system resources using a self-service model is called cloud-computing.
It sounds quite ethereal - the Cloud. But in reality, the Cloud is just a whole bunch of servers that live in “server farms” - big air-conditioned warehouses with racks and racks of servers.
Cloud computing has abstracted the need for networking, hardware upgrades, security, etc and is cheaper because of economies of scale providers are able to offer. You no longer need to employ that person to look after your servers. You use a company who manages that person, or people, for you.
Moving your services to the cloud means that you can be flexible and switch to new technologies quickly, avoiding upfront costs. And costs typically work on a sliding scale, instead of building for the maximum usage you buy for less usage and increase or decrease as appropriate.
As a developer, I can log into a cloud-provider, click a few buttons and somewhere in the cloud, a server is born (well, provisioned!). I can provision computing capabilities without the need for any other human intervention.
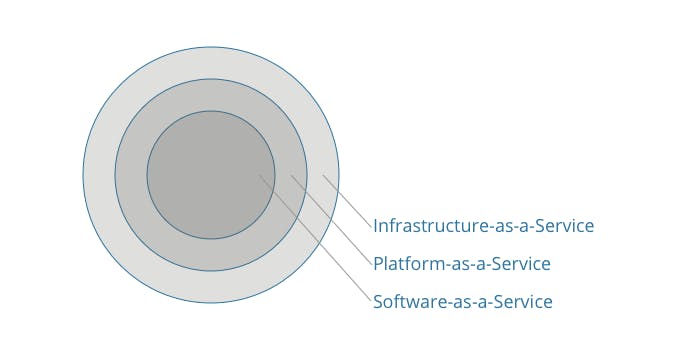
The cloud powers many services. We can classify them into:
- Infrastructure-as-a-Service (IaaS) – resources such as data storage, servers, and networking in a virtual environment.
- Platform-as-a-Service (PaaS) - allows developers to build custom applications online without having to deal with data-serving, storage, and management.
- Software-as-a-Service (SaaS) – applications which are accessible by people just by using a browser. So Google’s apps like Gmail, Google Drive, and Google Calendar are SaaS.
We can think of these “as-a-service” models as abstractions of functionality. Like layers of an onion.
With Infrastructure-as-a-Service - I don’t need to know or worry about the infrastructure - ie the machines and wires. And the providers guarantee the up-time so I don’t have to worry whether the machines are running.
Abstract that one level further, and I can use a Platform-as-a-Service provider who will provide not only the infrastructure – servers, storage and networking – but also middleware, development tools, business intelligence (BI) services, and database management systems. It’s all managed for me but I can still configure everything how I like.
Platform-as-a-Service providers such as Heroku or AWS Elastic Beanstalk - provide easy-to-use ways for developers to get their apps to market without having to worry about the infrastructure at all. There’s less to configure and think about, but you lose the ability to customise and you may pay more for the convenience.
Your experience of the Cloud is likely to be with the multitude of Software-as-a-Service (SaaS) applications. They abstract away everything apart from the key functionality all neatly packaged up in a subscription-based online app. Gmail is a great example of this. It’s got all the functionality of software but you use your browser to read your emails. SaaS is ideal for small businesses as they are typically bought on a pay-as-you-go basis and can scale per easily per number of users.
There are more as-a-Service models that do one thing well such as Content-as-a-Service or Payments-as-a-Service which may be different flavours of Platform or Software-as-a-Service models.
Developers can use Application Programming Interfaces or APIs to get services to pass data and interact with each other. Again, JavaScript is the lingua franca. Modern programming languages include code to generate and parse what we call JSON-format data. JavaScript Object Notation. So I can write code for a webpage, that interacts with an API to fetch data and then dynamically create HTML based on the results of what’s returned.
You’ve probably seen APIs used in this way when looking at a website that has a Twitter feed. But any machine-to-machine communication will use an API. A service like Netflix can use 700 “microservices” all talking together using APIs.
Part 3: What is Serverless?
Whereas cloud services have abstracted the need for hardware, Serverless services abstract the need to know any information about the server.
Serverless computing is a cloud-computing service in which the cloud provider runs the server, dynamically manages the allocation of machine resources and simplifies the process of deploying code into production. Rather than having to configure the server and the software that it needs to run server-side code, this is done for us. There are still servers, but we don't have to worry about them anymore.
Serverless services include computational power - a way of providing Function as a Service (FaaS), data storage, as well as databases. As well as a further reduction in costs, it means that developers can concentrate on adding value.
I can write my functions in Node.js, so once again, I’m writing this code in JavaScript, a language I’m already familiar with. All I need to access this function is an address on the internet that I can reach it at. To help with this, I can use tools that enable me to write code to define the infrastructure I need to hook up the function to the internet, and automatically deploy it.
With this Infrastructure-as-code, I write out the recipe for my services but the ingredients are mixed and the cake is baked for me. When it’s cooked, my function has an address on the internet (using an API Gateway) that I can reach from the client-side code, my simple static HTML, CSS, and JavaScript assets.
I can still use a dynamic approach and use templates and content managed systems to make producing front-end code efficient by using Static-site generators. Static-site generators only create the HTML, CSS and JavaScript when a change in code or content is detected, rather than an application that’s always running and producing the files on demand.
I find it really empowering that I can design and build web applications that I would have previously needed the help of a back-end developer, system administrators, and a whole host of IT staff. Now, I can just write and deploy code. It really feels like I’ve moved from being a front-end developer to being an engineer.
Should I go Serverless?
For me, the advantage of Serverless is that I’m able to deploy a suite of cloud-based services to provide back-end capability without having to worry about any of the set-up, maintenance or the cost of running servers. Serverless significantly reduces costs. I don’t have to provision or maintain any servers. And there is no software or runtime to install, maintain, or administer.
The beauty of all this is that, if my application experiences a lot of traffic - it can handle it. The Serverless provider produces more and more instances of my function as needed and it scales automatically.
This elasticity also means we also don't have to pay for idle capacity. There is no charge when your code isn’t running. If you are running a server, you pay for it to be running 24/7. With Serverless, you pay only when the function is being run.
There are downsides. For instance, I predominantly use AWS, and there is currently a 30-second limit to their API-Gateway so it's important that a function can complete in that time. It's not suitable for every type of processing.
If you integrate your Serverless architecture with legacy systems which don’t support such elasticity, downstream systems might not be able to scale as well as your Serverless architecture.
Serverless architecture is distributed — meaning it will consist of wiring together many services, like authentication, databases. Integrating many components in this way can lead to complex architecture.
People-first, not infrastructure-first
Whether you go down the Serverless route depends on your use case. It's imperative when making decisions about your organisations' infrastructure, not to start with the solution in mind.
An infrastructure-first approach restricts future capability. Too many business transformations start with buying an off-the-shelf solution without thinking about what users need. A well-known name might give you some comfort when shelling out big bucks, but without considering the people that use your service first, you run the risk of wasting a lot of money on a solution that can't add the value that your users crave.
A customer-centric organisation will seek to understand what their customers desire and hang technology choices off them. Modern frontend engineering advocates ‘loosely coupled’ architectures. Rather than having a single monolithic structure, you separate out the different parts of your system to give you flexibility, scalability and maintainability. You can swap out individual services as needed. And if one element fails, it doesn't take down the whole operation.
You might remember the Twitter Fail Whale. The Fail Whale appeared whenever one part of Twitter’s system became overloaded. These days, we don’t see the Fail Whale because Twitter has re-architected their site, breaking up the components into a mesh of siloed microservices. If one of these services break, you still get most of the functionality of Twitter.
It is important to realise that a Serverless approach brings with it a whole new paradigm of architectural design. This is a technology still in its early years. Although it’s been around long enough to be tried and trusted, it may be difficult to recruit developers with Serverless experience.
But you don't have to go fully-Serverless, it's a great way of complementing existing technology and validating ideas cheaply.
In our recent work with Women’s Aid, I used Serverless Functions in this way. We created a pilot to see how they could use a Live Chat service to hold discrete conversations with survivors of abusive relationships. Instead of spending a lot of money on technology upfront, we used an off-the-shelf consumer chat service to do most of the heavy lifting. We then use Serverless functions to provide the customisations we needed.
We created a queuing system to limit access to the service at busy times so that women weren’t waiting a long time unnecessarily. We showed average wait times so that women could make an informed decision whether they wanted to join the queue. And we sent automated messages to reassure them whilst they waited.
Creating a pilot in this way proved the need for the service and has enabled Women’s Aid to understand exactly what they need from a fully bespoke system before building it. They now know what it takes to operate live chat and can create a much more effective and efficient service.
As a Creative Technologist, I think Serverless is fantastic as I can use proof-of-concept prototypes to show how user needs can be served by technology. We can deploy scalable services quickly and innovate rapidly without spending a lot of money. There is a lot of value in getting technology in front of an end-user as soon as possible to get early feedback, and the reduced time to market that comes with Serverless lets us be quick and nimble.

Dave is an esteemed former member of the cxpartners team.